
Did you know your favorite website can detect when you’re browsing it in public transport and when you scroll it laying in your bed? Today we’ll learn how they can do it and how this info is used to fight bots.
I gave this talk at Google Developer Student Club Žilina, and CodeBeer in Bratislava last year. To be honest, I had already forgotten about it, but recently I found it in my notes, and damn, this stuff is interesting! So after a bit of editing and updates, here it is as an article.
A small disclaimer before we start: I didn’t work in a big company that manages bots or does bot protection, nor do I have any bots of my own. I learned all this as part of research for one of the projects I did for my client, found this stuff very fascinating, and I really wanted to share it with others. Just keep in mind it’s not a definitive guide and there are many, many more details to each technique covered here.
Table of contents
- Intro
- Simplest bot
- IP reputation & proxies
- TCP fingerprinting
- TLS fingerprinting
- JavaScript
- Headless browsers
- New headless
- Orchestraion frameworks
- Proxy detection
- Captchas
- Simple behavior analysis
- Advanced behavior analysis
- Further reading
Intro
We’ll be talking about web bots and their evolution. And by “web bots” here I mean both programs that imitate human users to perform some actions (like shitposting on social media) and scrapers that just collect information (usually imitating human users too).
While some bots might be very useful for the internet (like search engine crawlers or archivers), a lot of times it’s not the case. Site owners were fighting bots from the very beginning of the internet, and techniques to detect them evolved as bots became more sophisticated. Today we’ll cover the evolution of both bots and their detection techniques and see how this cat-and-mouse game unfold.
Simplest bot
Let’s start from the ground up. One of the simplest bots you can imagine is just a script that makes a request to the website using some HTTP client library or CLI program like curl or wget.
❯ curl -v http://httpbin.org/html
* Host httpbin.org:80 was resolved.
* IPv6: (none)
* IPv4: 52.45.33.43, 18.209.97.55, 34.198.95.5, 35.169.248.232
* Trying 52.45.33.43:80...
* Connected to httpbin.org (52.45.33.43) port 80
> GET /html HTTP/1.1
> Host: httpbin.org
> User-Agent: curl/8.7.1
> Accept: */*
>
* Request completely sent off
< HTTP/1.1 200 OK
< Date: Sat, 21 Jun 2025 06:53:08 GMT
< Content-Type: text/html; charset=utf-8
< Content-Length: 3741
< Connection: keep-alive
< Server: gunicorn/19.9.0
< Access-Control-Allow-Origin: *
< Access-Control-Allow-Credentials: true
<
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<h1>Herman Melville - Moby-Dick</h1>
<div>
<p>
Availing himself of the mild, summer-cool weather that now reigned in these latitudes, and in preparation for the peculiarly active pursuits shortly to be anticipated, Perth, the begrimed, blistered old blacksmith, had not removed his portable forge to the hold again, after concluding his contributory work for Ahab's leg, but still retained it on deck, fast lashed to ringbolts by the foremast; being now almost incessantly invoked by the headsmen, and harpooneers, and bowsmen to do some little job for them; altering, or repairing, or new shaping their various weapons and boat furniture. Often he would be surrounded by an eager circle, all waiting to be served; holding boat-spades, pike-heads, harpoons, and lances, and jealously watching his every sooty movement, as he toiled. Nevertheless, this old man's was a patient hammer wielded by a patient arm. No murmur, no impatience, no petulance did come from him. Silent, slow, and solemn; bowing over still further his chronically broken back, he toiled away, as if toil were life itself, and the heavy beating of his hammer the heavy beating of his heart. And so it was.—Most miserable! A peculiar walk in this old man, a certain slight but painful appearing yawing in his gait, had at an early period of the voyage excited the curiosity of the mariners. And to the importunity of their persisted questionings he had finally given in; and so it came to pass that every one now knew the shameful story of his wretched fate. Belated, and not innocently, one bitter winter's midnight, on the road running between two country towns, the blacksmith half-stupidly felt the deadly numbness stealing over him, and sought refuge in a leaning, dilapidated barn. The issue was, the loss of the extremities of both feet. Out of this revelation, part by part, at last came out the four acts of the gladness, and the one long, and as yet uncatastrophied fifth act of the grief of his life's drama. He was an old man, who, at the age of nearly sixty, had postponedly encountered that thing in sorrow's technicals called ruin. He had been an artisan of famed excellence, and with plenty to do; owned a house and garden; embraced a youthful, daughter-like, loving wife, and three blithe, ruddy children; every Sunday went to a cheerful-looking church, planted in a grove. But one night, under cover of darkness, and further concealed in a most cunning disguisement, a desperate burglar slid into his happy home, and robbed them all of everything. And darker yet to tell, the blacksmith himself did ignorantly conduct this burglar into his family's heart. It was the Bottle Conjuror! Upon the opening of that fatal cork, forth flew the fiend, and shrivelled up his home. Now, for prudent, most wise, and economic reasons, the blacksmith's shop was in the basement of his dwelling, but with a separate entrance to it; so that always had the young and loving healthy wife listened with no unhappy nervousness, but with vigorous pleasure, to the stout ringing of her young-armed old husband's hammer; whose reverberations, muffled by passing through the floors and walls, came up to her, not unsweetly, in her nursery; and so, to stout Labor's iron lullaby, the blacksmith's infants were rocked to slumber. Oh, woe on woe! Oh, Death, why canst thou not sometimes be timely? Hadst thou taken this old blacksmith to thyself ere his full ruin came upon him, then had the young widow had a delicious grief, and her orphans a truly venerable, legendary sire to dream of in their after years; and all of them a care-killing competency.
</p>
</div>
</body>
* Connection #0 to host httpbin.org left intact
</html>%And as you can guess, such programs are easily detectable. You see, all HTTP clients send User-Agent header when making a request, with info about the client. And so curl, wget and all HTTP client libraries voluntarily tell the website who they are. Which makes it extremely easy to detect requests from such bots and block them.
> GET /html HTTP/1.1
> Host: httpbin.org
> User-Agent: curl/8.7.1You, of course, can change this and make them send a user agent that looks like a real browser (or any other string):
❯ curl -v -H "User-Agent: I'm Google Chrome trust me bro" http://httpbin.org/html
# ...
> GET /html HTTP/1.1
> Host: httpbin.org
> Accept: */*
> User-Agent: I'm Google Chrome trust me bro
# ...But this won’t be enough. Unlike curl, browsers provide quite a lot of additional info in headers when making a request: the user’s languages, accepted encodings, et cetera. In order to mimic a real browser, the bot should provide all of them too. Otherwise, you’ll get blocked.
IP reputation & proxies
Another easy way to detect a bot is to check its IP address. If you need a bot to run for a long time, or if you run multiple bots, it makes sense to host them in the cloud rather than on your laptop.
But address ranges for all major cloud providers (like Google Cloud, Digital Ocean, and others) are well-known. When a website receives a request from such an IP, it can be sure it’s coming from a bot or other automated software.
While it’s okay if you’re hitting some API (which is made to be used by software), it’s a different story if you’re trying to mimic a human user. Different web services have different tolerance levels for such clients: some will outright block access from datacenter IPs, others will give such clients minimal benefit of the doubt.
Either way, if you want your bot to work at least somewhat reliably, you’ll need proxies. And not every proxy will do. All proxies available openly on the internet have their IP reputation already at rock bottom. So you’ll need private proxies, which usually means they will cost you some money. To look convincing, these proxies should be residential, meaning their IP address should belong to an IP range of residential internet service providers.
A web service trying to protect itself will actively check if you’re using proxies. We’ll cover more techniques when we get to the JavaScript, but even before serving you a response, the web server will check your IP reputation, and if there are any doubts, it also might try to probe your ports. If one of the ports usually used by proxies (like 1080) is open, it’s a strong signal that this connection is proxied.
And probably you will need a lot of proxies. Because sooner or later service will ban your IP. It might be because of other red flags your bot raised, or just because of abnormal behavior. This is usually solved by using rotating proxies. The proxy provider will regularly change the set of proxies available to your account, so it becomes harder to detect bots as their activity gets spread on different IPs.
A special place here is taken by mobile proxies. Because of the way mobile carriers work, many clients will share the same IP address. In big cities, a single IP can be shared by hundreds of devices. And banning such address because of one pesky bot will also block quite a lot of real users. Web services know about this and are more hesitant to block mobile IP addresses.
TCP fingerprinting
But let’s assume you found some nice proxies and fixed your bot’s user agent. Do your hardships end here? Of course, not.
Chances are high, you decided to use User-Agent from Windows. Makes sense, it’s still the most popular desktop operating system. And you probably run your bot on a Linux server because it’s cheap. Bad news is this can also be detected.
To make an HTTP request, the client needs to establish a TCP connection first. HTTP is an application layer network protocol, meaning that it’s mainly used and interpreted by applications, like an HTTP client or web server. TCP, on the other hand, is a transport protocol, it’s managed by the operating system. TCP packets wrap application layer packets (like HTTP or FTP) and transport them to the destination, where they are unpacked and application layer packets from them forwarded to the receiver application.

Application doesn’t control TCP packets; they are managed by OS. And each OS tends to handle TCP a bit differently.
So knowing how each system composes its TCP packets allows you to analyze incoming traffic and, with a good level of certainty, detect if the packet comes from a Linux machine, Windows, or Apple device. Having this info, you can compare it with the provided User-Agent and detect dishonest bots.

Proxy servers might change your TCP fingerprint too. So it’s important to choose either proxies with OS matching your user-agent or proxies that don’t change your fingerprint.
TLS fingerprinting
Similar to TCP fingerprinting, we also have TLS fingerprinting. TLS is a protocol used to encrypt communication. That’s what adds S to your HTTP. And similarly to TCP, before sending any data using TLS, client and server do a handshake when they tell each other which ciphers they know and decide on which one to use, so both parties will be able to communicate.

And so every system and browser might have slightly different sets of supported ciphers, different supported TLS versions, and different available TLS extensions. This info can then be used to detect the client’s OS and compare it with one provided in the user agent or deducted from TCP fingerprinting.
JavaScript
All detection techniques mentioned so far can be used before the server even starts generating a response for the request. And while they allow to detect some of the less sophisticated bots, it’s usually not enough.
Conveniently, bot detection services have a very powerful tool at their disposal: JavaScript. With its help they are able to collect a ton of info from the user’s browser and send it back to the server to decide if it looks suspicious or not. To avoid detection, bots will need to not only execute JavaScript but also have a legit browser environment that looks realistic enough.
Can you just not execute JavaScript? Well, you could try, but since almost all legit clients execute JavaScript, clients that do not execute JavaScript look suspicious.
Luckily for bot developers, there are projects that allow you to programmatically control a real browser (like Chrome or Firefox). Now, instead of making HTTP requests, you’re controlling the whole browser, giving it orders to “open this page”, “click that button”, and so on.
One of the oldest projects that is still around is Selenium. Its main use case is testing, but it is also widely used to build bots. More recent (and more popular) names in the town are Puppeteer and Playwright.
These tools use Chrome DevTools protocol to control Chrome and wrap it into a convenient API. Playwright and Selenium also work with other browsers, but Chrome is by far the most popular one.
Headless browsers
Bots usually run Chrome in headless mode. In this mode, Chrome doesn’t show any UI, so you can run it on servers without a graphical environment. Problem is, this is a separate implementation of Chrome. It’s not “Chrome, but don’t open any windows”, it’s separate browser built with code from Chrome. And because of this, there were subtle differences that helped to distinguish Headless Chrome from a normal browser.
For example:
- Headless Chrome has the special property
navigator.webdriverset totrue, while in normal browsers it’sfalse. - Default User-Agent also includes info about headless mode.
navigator.pluginsis empty, while in normal browsers there are always a few plugins there- Headless Chrome doesn’t have a global
chromevariable, which is used to communicate with installed extensions and measure page loading times. - Headless browser reports the same specific video card in WebGL APIs.
And so on and so on. There are quite a lot of them.
Most of them can be patched. For example, navigator.webdriver can be removed by enabling a special flag in Chrome. For others, you can set up a code snippet to run before page scripts are run. This snippet could overwrite navigator.plugins to look a bit more natural. So it’s not that hard to patch them.
But the sheer number of discrepancies is huge. And you need to patch them all, because even a single unpatched hint will blow your cover. To add to that, you need to remember that JS can be executed in multiple contexts: page scripts, workers, and service workers. So you need to patch hints there too. And if some bot detection company finds a new hint, it might require a lot of work for a bot developer to find out what exactly gave his bot away.
New headless
Fortunately for bot developers, in 2021 Google started working on a new headless mode for Chrome and made the first public release in April 2023. The new mode is built directly upon Chrome, rather than being a separate implementation. This time it’s Chrome for real. And so it doesn’t have all the flaws of the original Headless Chrome, which makes it harder to detect.
Orchestraion frameworks
But it’s not all sunshine and rainbows for bot developers. While headless browser itself now looks a lot like a real thing, they are still managed by orchestration software like Selenium or Playwright, the presence of which adds to “attack surface” which can be used to detect automation.
By default, these instruments use a particular browser version, which isn’t always the same as the latest stable version. This too might be used as an additional factor in the detection. And by default they use Chromium, not Chrome which is used by most of the real users.
Moreover, Selenium, Puppeteer, and Playwright all pass a specific set of flags to the browser, which modifies its behavior. They are all there for a reason. For example, you wouldn’t want your browser to do background activity (like checking for updates) or try to sync to a Google account, so these frameworks disable this functionality by passing corresponding flags. But some of these flags modify browser behavior in a way that can be detected by JavaScript on the page. For example, Playwright disables lazy loading for iframes. It makes sense if you’re testing your web app with Playwright, but it also can give the website a hint about the browser being controlled.
IPC flooding
One of my favorite flags is --disable-ipc-flooding-protection. It’s used by all major frameworks. In Chrome architecture, each tab gets its own process where its code is run. This provides an additional level of security, as a compromised tab can’t easily mess with other tabs or with a central process. If some process needs to interact with another process, they use Inter-process Communication (IPC) to pass messages between them.
IPC is a relatively expensive operation, so it can’t be used excessively, as this might hang up both processes. And taking into consideration that fact, that usually tab communicates with the central Chrome process and not other tab, hanging it won’t be good at all.
Fortunately, IPC is used mostly in browser internals, so Chrome developers have control over how often messages are sent. But there are a couple of JavaScript functions that trigger IPC communication, like window.history.pushState. So to prevent abuse from malicious sites, Chrome implements flood protection. If a site calls such a function more than 200 times in a short period of time, it will get a warning, and Chrome will ignore all subsequent calls to this function for the next few seconds.
Sites can use this not only to detect users who have flooding protection disabled (which are very likely bots), but also actively sabotage any attempts to scrape information by overloading and freezing their browser.
Proxy detection
Huh? Didn’t we cover this already? Well, yes, but now we have JavaScript, and the ability to execute JavaScript significantly expands ways to detect proxies. And while usage of the proxy doesn’t mean it’s 100% bot, it will be used as one of the factors to decide how “trustworthy” this client is.
Latency
Let’s start with latency checks. Let’s recall the TCP handshake. The receiving web server can measure latency by checking the timing of the TCP handshake. However, since the proxy server establishes its own connection to the receiving web server, we’re essentially measuring latency between the proxy and web server.
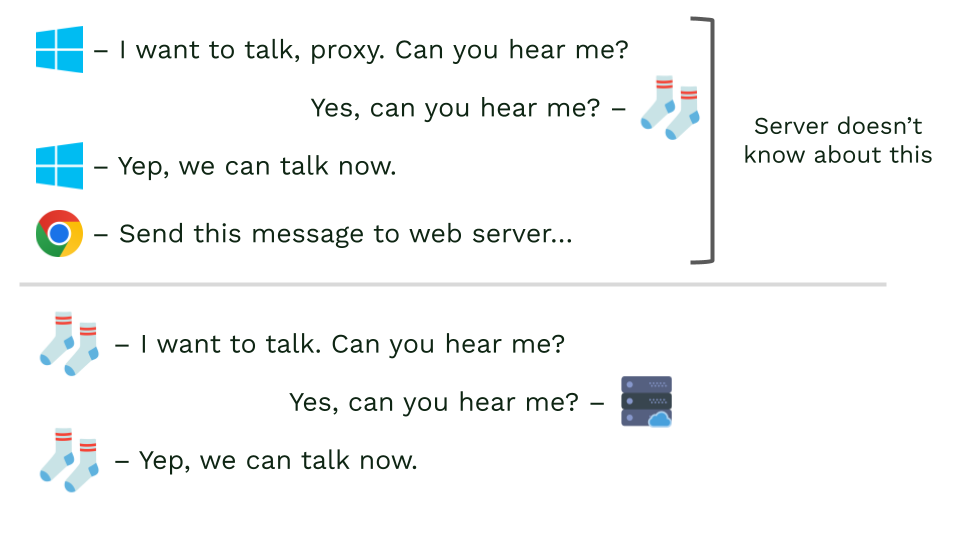
But there is also latency between proxy and client. And with JavaScript, website can measure total latency (i.e., how long it takes to transmit a packet from client to web server) by using WebSockets. If it takes significantly longer than the observed TCP handshake, it’s a clear sign that there is a proxy (or even multiple proxies) in between. Learn more.

WebRTC leaks
Another way to blow bot’s cover is WebRTC. WebRTC is technology used by browsers to enable real-time peer-to-peer communication. And to communicate with peers, you need to know both your and their addresses. To help with it, there is STUN protocol. Put simply, it’s a public server with a known address, to which you can make a request and ask “hey, what is my IP?”.
WebRTC (including STUN) works over UDP. And it so happens that most of the proxies don’t support UDP. So, by default, Chrome will send WebRTC requests directly without proxying them, revealing your real IP to JavaScript, which can forward it to the website. The cautious website then will compare the IP it received the initial request from and the IP it got from JS. If they mismatch, that might mean there is a proxy in the middle.
To mitigate this, the bot developer needs to set up his Chrome to route RTC requests through proxy if it supports UDP or not route them at all. But many bot developers miss this.
DNS leaks
Yet another way to detect proxies is to check for DNS leaks. If proxy/VPN is misconfigured, the browser still might use the default DNS provider to convert domains into IP addresses. But this check is harder to implement, as it requires you to manage your own Authoritative nameservers.
It works this way: you generate a few random subdomain names like asfgew2134.leak.mydomain.com and make requests to them from JavaScript. Since browser didn’t make any requests to this domain before, it needs to resolve it first. The browser sends a request to DNS, which in turn sends a request to your authoritative nameserver. You save info about the DNS resolver address and its location in the database and return the IP of your server. The DNS resolver returns this IP to the browser, which now makes a request to your server. On the server, you save the client’s IP address and location and compare it with the IP and location of his DNS resolver.
If a DNS resolver isn’t some global service (like Google or Cloudflare), then it’s likely a DNS provided by the client’s ISP. Comparing their locations, you can roughly infer if the client is using a VPN or proxy because it looks suspicious when the client from Slovakia uses some noname Vietnamese DNS resolver.
This can be avoided if the VPN provider also provides their own DNS resolvers that match location with their exit gateways. And to a lesser extent, this can be fixed by using popular DNS resolvers like Google’s 8.8.8.8 or Cloudflare’s 1.1.1.1. But those services might implement location-based routing, so your DNS requests might be served by a server which is physically closer to you (to lower the latency) which also might blow your cover.
Timezones
And lastly, there is a simple check for browser timezone. JavaScript can get your browser timezone and send it to the server, where it’s compared with assumed timezone based on your IP location. If they mismatch — that will be used as one of the hints that you’re using a proxy.
Captchas
We covered quite a lot of ways to detect bots, but didn’t even mention one that immediately comes to mind when you think about fighting bots. It’s time to talk about captchas.
You know what is captcha, I know what is captcha, but let me set the stage. Unlike previous methods, captchas aren’t used for detection of bots per se, they are used for protection from bots. Captcha is a challenge, with a task that should be (relatively) easy to do for a human and close to impossible (at least with adequate resource constraints) for a machine. In early days, that was guessing what is written in distorted pictures with noise. Nowadays, captchas come in all shapes and forms.
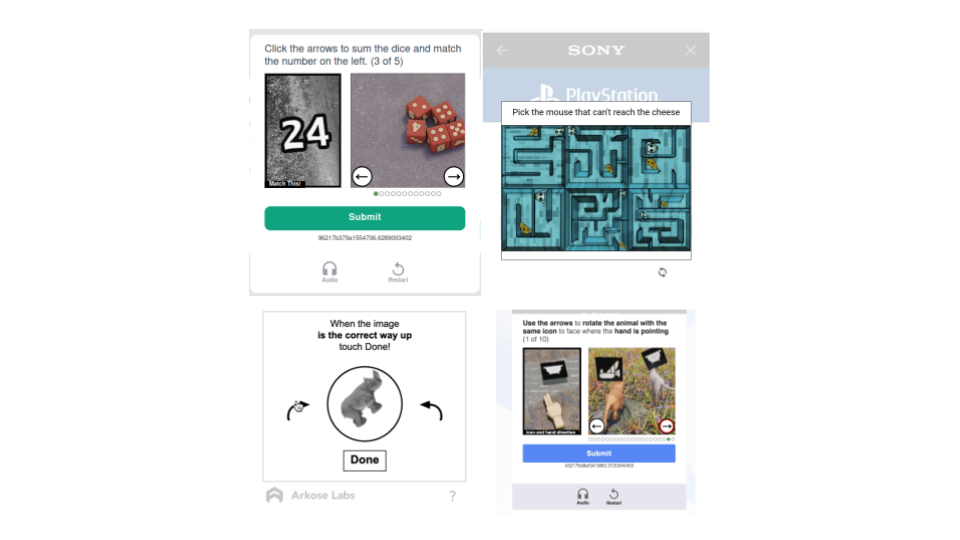
These challenges are indeed hard to solve for bots (though in 2025 even this is questionable), yet captchas usually don’t impose huge inconvenience for them. How so? Because they outsource solving captchas to real humans.
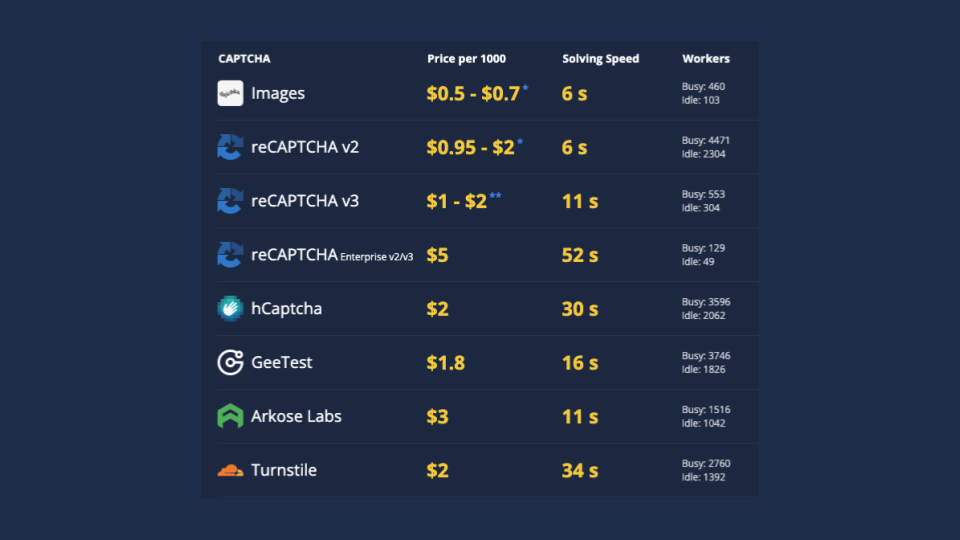
There are multiple services that employ workers in low-income countries to solve captchas and provide an API for developers to automate this process. For developers, this costs around 1–2 dollars per one thousand captchas, which is extremely cheap.
Proof-of-work
Recently there were a few novel captcha projects that used proof-of-work. These captchas don’t require user interaction, rather they require the user’s device to do some fixed amount of cryptographic calculations to pass this captcha. This captcha doesn’t try to block bots, but rather to make them not viable economically.

With such captchas, it’s crucial to select the correct amount of work required to pass it so users on less powerful devices will still be able to use the service. However, if you set it to low, this will make it easy to just comply with the captcha for bots that run on more powerful servers. And servers aren’t expensive, either. So unless you’re trying to prevent a huge spam attack, proof-of-work captchas aren’t very effective.
Behavioral captcha
Another type of challenge is behavioral captcha. It’s this weird captcha where you just need to click “I’m not a robot”. If you ever questioned, “That’s all? Where are pictures of cars I need to select? Do they just trust me?”, that’s the one. Examples of such captchas are Cloudflare Turnstile and Google’s Recaptcha (this one might still ask you to select cars, though).
Well, they don’t really trust you. These captchas employ a plethora of techniques to check if you’re a bot. This includes checking your browser for weird things (e.g. navigator.webdriver), proof-of-work challenges, and behavior analysis, which we’ll cover in a minute. And based on the results, they decide if your browser and your behavior look legit.
Those are, essentially, full-fledged bot detection services with a minor difference: those challenges work as a gate to particular parts or features of the website instead of monitoring the client continuously. And because of this, they can be bypassed by the same captcha solving services mentioned earlier. Your bot will send a task to a such service, where a human will open the page in a real browser and pass the challenge. The captcha will produce a key which later will be used by the server to check that the client actually passed the challenge. This key is transmitted back to the bot, which uses it to access the website and do its business.
Simple behavior analysis
So we already covered quite a few techniques. But all that was about tech, about the software and hardware you’re using to access the website. There is one more approach to bot detection. Instead of looking for discrepancies in the client’s environment, we can look at their behavior.
You see, humans, unlike machines, are hella slow and inefficient. We do a lot of extra actions when browsing the web. For example, while reading, you might follow sentences with the cursor. Or you might make mistakes when typing long text.
Machines do actions in fractions of a second, never mistype, and don’t do unnecessary actions. And that is precisely what gives them away. Bot detection services will monitor user actions with JavaScript and, based on those, decide if behavior looks human-ish.
Let’s explore by example, starting with the mouse. As humans, we generate a lot of unnecessary mouse movement. And we move the mouse in all different curves and trajectories. Bots usually don’t bother with this, they generate mouse movement only when they intend to click something, and even then it’s usually a very quick move in a straight line, which is easily detectable. And when it comes to clicking, bots by default click exactly in the center of an element, and the delay between mousedown and mouseup events is too small, which is not how humans click at all.
When it comes to typing, bots usually type at constant high speed, and delay between keydown and keyup events is also very short. But humans have noticeable delay between pushing and releasing the key, as well as between releasing and pushing the next key. While delay between pushing and releasing the same key is more or less stable (with a small deviation), delay between releasing the key and pressing the next one is more varied.
Even if you put a random delay into your bot, it still can be detected because (a) in long enough texts, random pauses will be uniformly distributed over the spectrum and (b) delays between human typing aren’t random, they depend on distance between keys.
Another detail, specific to bots pretending to be mobile devices, is lack of device motion. Normally, on mobile, your browser will generate deviceorientation events when you move and will emit devicemotion events with info about device acceleration every 10ms. Headless Chrome doesn’t emit those events, and so websites can easily detect if you’re lying to them. By the way, this, in combination with an IP check, is how your favorite site can deduce whether you’re lying in bed or commuting.
The last example of the situation when bots function too efficiently is how they interact with new elements on the page. Even if a human is eagerly waiting for some button to appear, it will take a few dozens of milliseconds (and probably even a few hundreds) for them to click on it when it appears. But when bots wait for some element to appear, they will click on it almost instantly.
Advanced behavior analysis
But naive checking for human-like delays between key presses only takes you so far. Once bots start to use better tricks, you need to come up with even better techniques to detect bots.
However, as a bot detection service, you would have a big advantage. Well, assuming you’re actually good at your job and have real clients, that is. Anyway, you would have access to a lot of behavioral data from sites under your management. And using previously described techniques, you can filter this dataset to include only behavior that is very likely coming from a real human or likely coming from a bot.
What would you do with all this data? Train some AI, of course! Now, I’m not talking about some giant LLMs that are on the hype now, but rather a lot smaller and more specific models. You could use human and bot behavior data to train a model, which then can be used to classify or/and score the behavior of new site visitors.
And this model can be quite effective in detecting bots. It will learn patterns in human behavior that are hard to imitate even for more advanced bots. For example, it might learn that humans tend to move the mouse in specific trajectories when navigating the page. Or that there are certain patterns in timings between keystrokes when typing.
This, of course, requires a lot more resources and knowledge than using simple detection algorithms, but it also hardens your defense. It’s not meant to be “end game” of bot detection service but rather one of factors that, in combination with other techniques described today, composes a capable bot detection service.
Further reading
Unfortunately, there is not that much good material on this topic available on the internet (mostly marketingy slop or basic tutorials). But one specific website helped me a lot while I was preparing this material, it’s incolumitas.com. Probably best source of info on this topic on the public web. Unfortunately, Nikolai doesn’t actively post there anymore, but his existing archive is an excellent source to dive deeper into this topic.


